Method
[Paper] [Code]
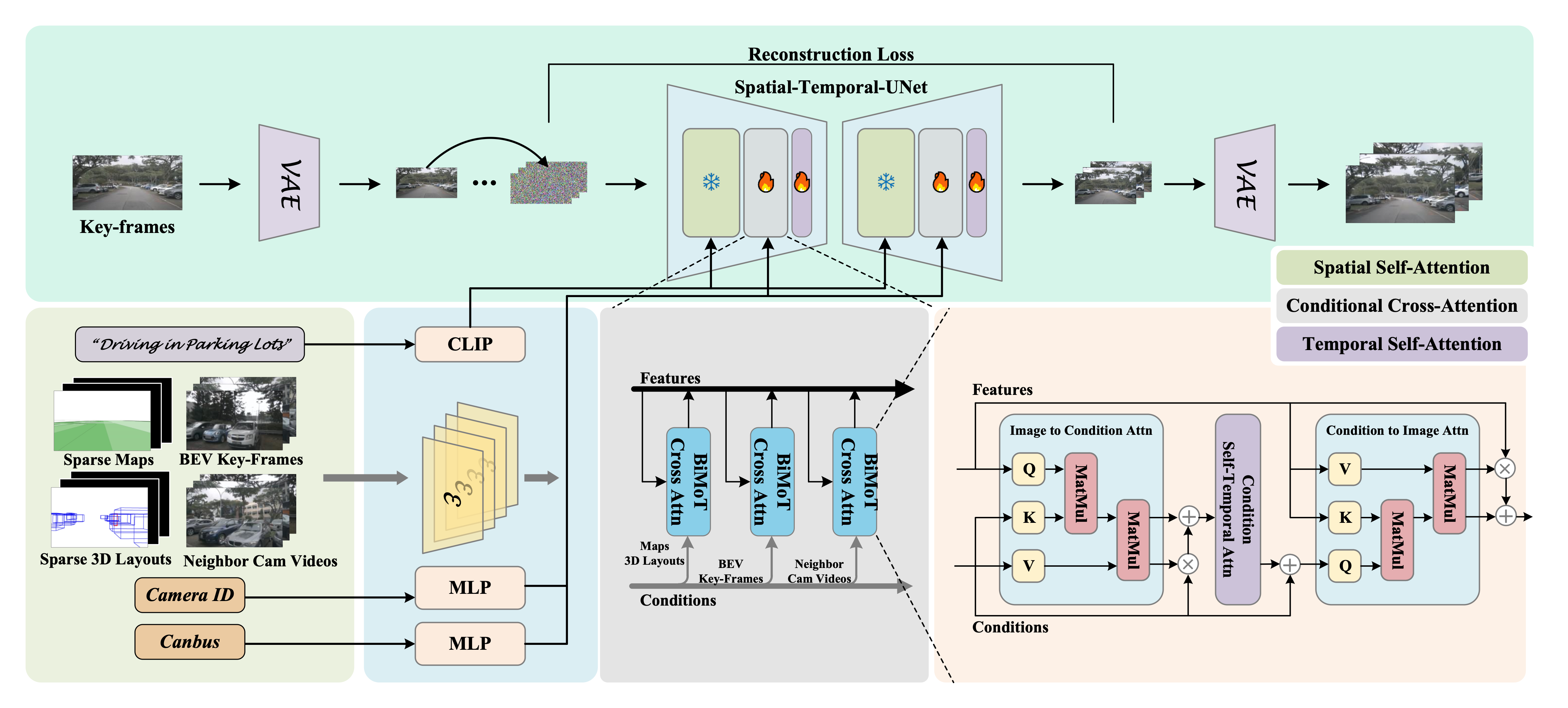
Recent advancements in generative models have provided promising solutions for synthesizing realistic driving videos, which are crucial for training autonomous driving perception models. However, existing approaches often struggle with multi-view video generation due to the challenges of integrating 3D information while maintaining spatial-temporal consistency and effectively learning from a unified model. We propose DriveScape, an end-to-end framework for multi-view, 3D condition-guided video generation, capable of producing 1024 x 576 high-resolution videos at 10Hz. Unlike other methods limited to 2Hz due to the 3D box annotation frame rate, DriveScape overcomes this with its ability to operate under sparse conditions. Our Bi-Directional Modulated Transformer (BiMot) ensures precise alignment of 3D structural information, maintaining spatial-temporal consistency. DriveScape excels in video generation performance, achieving state-of-the-art results on the nuScenes dataset with an FID score of 8.34 and an FVD score of 76.39. We will make our code and pre-trained model publicly.
First row: Generated panoramic video. Second row: Sparse layout condition, black represents no layout condition at that moment.
| Model | Spatial Res. | FPS | Sparse Condition |
|---|---|---|---|
| Drive-WM | 192 × 384 | 2 | × |
| WoVoGen | 256 × 448 | 2 | × |
| Delphi | 512 × 512 | 2 | × |
| GenAD | 256 × 448 | 2 | × |
| MagicDrive | 272 × 736 | - | × |
| DriveDreamer 1&2 | 448 × 256 | 2 | × |
| DriveDiffusion | 512 × 512 | 2 | × |
| Panacea | 256 × 512 | 2 | × |
| Ours (DriveScape) | 576 × 1024 | 2~10 | ✓ |
We simulate a scenario where the following vehicle rear-ends your car.
We simulate a rear-end collision scenario with the leading vehicle.
left:edited videos; middle: structured input; right: original videos;
The video shows a dark street at night with a car driving down the road. The street is illuminated by streetlights. The blue vehicle is passing a junction in the image. The ego vehicle is moving, as it is seen driving down the street in the video.
The video shows a city street with a mix of vehicles, including cars, and a truck .The weather appears to be cloudy, and the lighting is dim.
left:generated videos; middle: structured input; right: original videos;